
La sauvegarde régulière des données d’un site est d’une importance capitale afin de parer toute éventualité de perte d’informations. Lors d’un transfert du contenu d’un site vers un autre emplacement, il faudra nécessairement réaliser une sauvegarde manuelle afin de pouvoir l’envoyer à sa destination … jusqu’à ce que l’une de ses sauvegardes soit corrompue et que le point de départ soit supprimé, voici mon récit.
Contexte
À la demande du client et de son cahier des charges, nous avions besoin de mettre en place un site sous le système de gestion de contenu WordPress et PrestaShop. Afin de rendre la gestion plus aisée et regrouper ce qui va ensemble, le domaine domain.be (domaine d’emprunt afin de garder l’anonymat du client impacté) prend la tête d’un espace web sous Plesk. Pour garder un minimum de séparation entre les CMS, le système dédié au blogging et création de sites vitrines a été créé sur le sous-domaine blog.domain.be et attaché à l’espace web de domain.be qui lui, possède le système dédié à l’achat en ligne.
Plesk est un tableau de bord pour gérer des serveurs.
Quelques jours plus tard, le client demande à échanger le contenu du domaine avec celui du sous-domaine et pour réaliser cette tâche, plusieurs solutions sont possibles :
- modifier la racine des deux sites.
- pointer les DNS vers les domaines concernés mais ça allait engendrer une boucle de redirection.
- transférer – manuellement – le contenu.
DNS pour Domain System Name, système de noms de domaine en français, est un service qui permet lier un nom de domaine avec une ou plusieurs adresses IP. C’est aussi lui qui s’occupe, lorsque vous recherchez un domaine tel que le mien (
lennyobez.be), de rechercher son IP.1
N’ayant guère le choix quant à la solution employée J’ai appris plus tard que lorsqu’on doit transférer deux domaines du même espace web, on peut tout simplement modifier la racine du site 😬 bref, je me lance illico-presto dans la sauvegarde des fichiers provenant du FTP ainsi que des données de la base de … données. Comme le domaine, son sous-domaine ainsi que toutes les configurations ont été établie sur un seul et unique espace web, je prends la décision, une fois la sauvegarde récupérée, de supprimer cet espace afin de le recréer, il vaut mieux parfois recommencer de zéro.
FTP pour File Transfer Protocol, protocole de transfert de fichier en français, est une technique de communication permettant d’ajouter, modifier ou supprimer des fichiers à distance.2
Maintenant que le nouvel espace web a été créé et paramétré, je me lance dans le téléversement de mes sauvegardes afin de restaurer tout ce qui a été précédemment réalisé mais sur leur nouveau domaine respectif jusqu’à ce que je remarque que l’une des sauvegardes produit une erreur : la base de données WordPress, je l’ouvre afin de vérifier ce qu’il en est et je remarque qu’elle est corrompue.
La seule sauvegarde de cette base que je possède, c’est celle qui est corrompue car les sauvegardes automatiques de l’espace web ont été supprimées avec l’ancien espace web, je suis dans de beaux draps … Comment vais-je bien pouvoir récupérer le texte et la mise en page du site ?
Le cache
C’est au bord du précipice que l’homme fait preuve d’ingéniosité.
– Lenny Obez
Qu’est-ce qui stocke une partie des informations que l’on consulte ? Le cache, bien évidemment ! À première vue, j’ai 4 possibilités :
Récupérer le cache créé par un script du site
Les configurations étant trop nombreuses pour les énumérer, je vais faire l’impasse sur cette section. En tout cas, un développeur saura et pourra facilement récupérer le cache qui devrait être soit sur votre FTP ou soit sur l’un de vos CDN. De mon côté, je n’ai pas activé le cache car le site de mon client était toujours en construction.
Être en cache Google et le récupérer
Les robots d’indexation mettent en cache toutes les pages qu’ils visitent mais ne conservent que la dernière version visitée, pour bénéficier d’une visite de ces robots, il faudra au préalable être référencé sur le célèbre moteur de recherche, cela peut se faire naturellement grâce à l’âge et la popularité de votre domaine. Si vous n’avez aucun des deux, vous pouvez toujours faire une demande d’indexation sur 🔗 Google Search Console.
Si votre site est en plein développement et en ligne, il est déconseillé de demander du référencement et si celui-ci est toujours à l’étape embryonnaire (= local), le passage sera impossible. Comme le site de mon client était toujours en développement – et à ses débuts, qui plus est ! -, je n’ai pas demandé le passage de ces fameux robots et je ne peux donc pas bénéficier du cache de Google.
Si vous désirez apercevoir le cache Google de votre site, vous pouvez y accéder en tapant cache: devant l’URL de votre site / page.
Utiliser les archives d’Internet
Le projet très intéressant d’archive.org consiste à enregistrer une copie de chaque version de chaque site du monde mais il faudra lui renseigner la ou les nouvelles pages que votre site possède. Dès que c’est fait, son robot d’indexation passera une fois par jour sur les pages que vous lui aurez donné afin de vérifier si il y a eu des changements ou pas, s’il y en a eu, il récupérera tout le code et le conservera indéfiniment, pratique si vous désirez voir l’évolution de votre site.
Encore une fois, je n’ai pas enregistré le site dans l’archive afin que les visiteurs dont la curiosité s’envole ne puissent pas observer les premières étapes de développement du site.
Visionner et obtenir le cache de votre navigateur
Le développement d’un site web nous oblige fort heureusement à visiter chacune des pages de notre site et donc à créer un cache du côté navigateur, c’est sur ce cache que je vais baser ma récupération de données.
Tout d’abord, je désire visionner le cache de mon navigateur et je me rends pour cela sur :
- chrome://cache pour le navigateur Chrome.
- about:cache pour le navigateur Firefox et il faut ensuite cliquer sur le lien
List Cache Entries. - opera:cache pour le navigateur Opera.
Peu importe le navigateur utilisé, vous allez arriver sur une page remplie de liens hypertextes.

Des beaux liens hypertextes colorié en bleu et souligné, comme on en fait plus.
Au cas-où qu’il y ait des informations confidentielles sur ces liens – méthode GET pour les connaisseurs -, l’image a été volontairement floutée et rognée, pour gagner de la place.
Dans les différents langages de programmation, il y a plusieurs façons de transmettre des informations et l’une d’entre-elles est la méthode GET – ce terme est employé pour PHP -, elle transmet les données via les liens
Afin de retrouver mes fichiers, je vais réaliser une recherche sur la page via la combinaison de touches CTRL + F et cibler tous les fichiers dont j’ai besoin, je sais que je nécessite le contenu texte de plusieurs pages ainsi que du code de mise en page – CSS – qui était en partie stocké dans la base de données – afin de réaliser plus facilement du versioning -. Une fois que j’ai trouvé un fichier qui est intéressant, je l’ouvre pour découvrir son contenu.
Le versioning est le fait de conserver une copie de chaque version de développement et de les classer dans des branches.
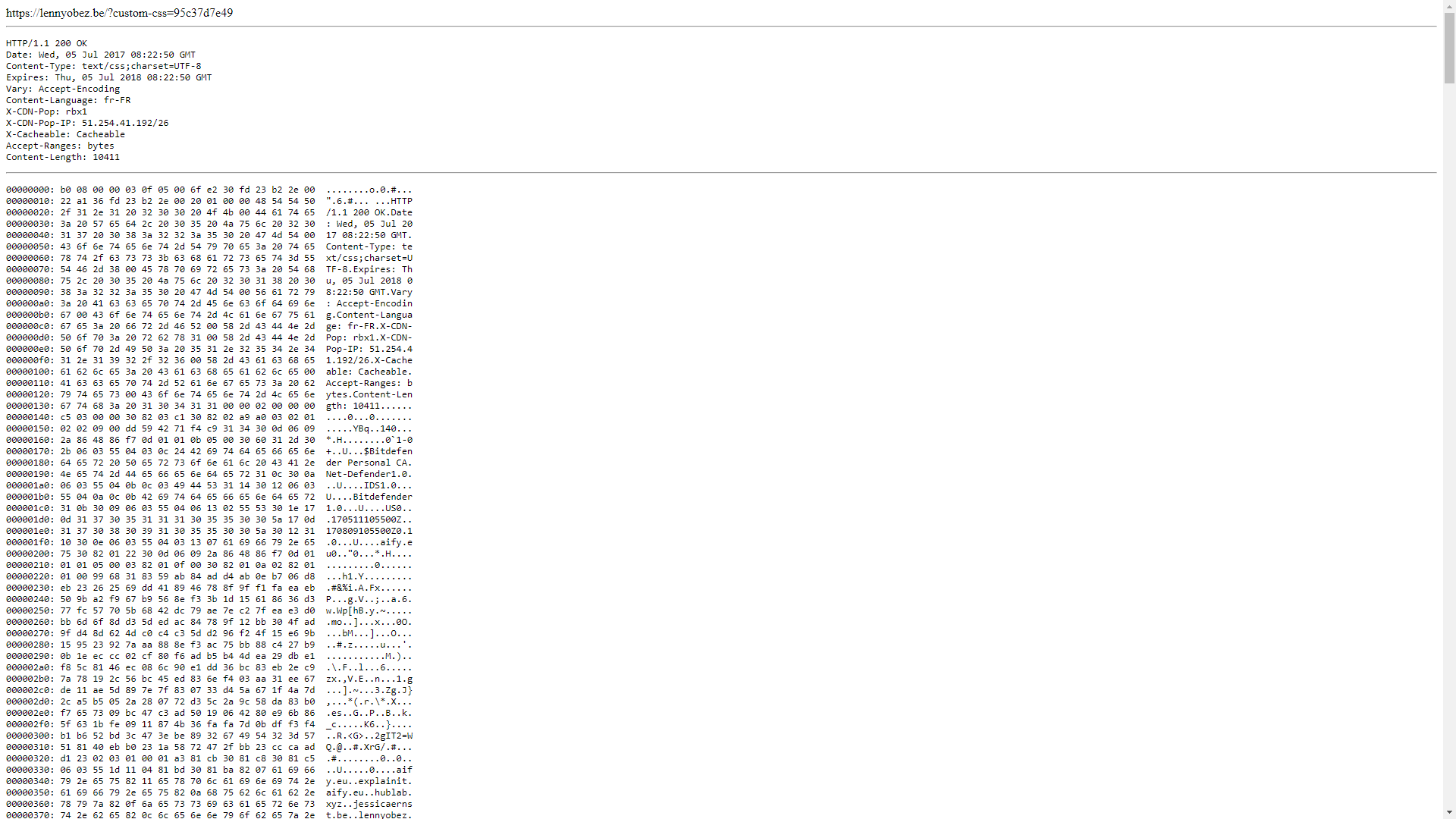
Nous voilà maintenant sur le cache d’une page qui est divisé en 4 parties distincts séparées par une ligne horizontale :
- L’URL du fichier « caché » – qui définit le nom -,
- Les informations du fichier cache :
- HTTP : le code réponse HTTP,
- Date : la date de récupération ou de création – si ce dernier a été pré-créé -,
- Content-Type / Charset : le type de fichier ainsi que sa méthode d’encodage,
- Expires : la date d’expiration,
- Vary : déclaration si le contenu peut être compressée via le navigateur (GZIP),
- Content-Language : langage du contenu,
- X-CDN-Pop – propre à OVH – : l’identifiant du CDN,
- X-CDN-Pop-IP – propre à OVH – : l’adresse IP du CDN,
- X-Cacheable – propre à OVH – : indique si le fichier peut être mis en cache ou non (si ce dernier est dans votre cache, il est logique que la valeur sera toujours sur
Cacheable), - Accept-Ranges : déclaration si la page peut recevoir des requêtes partielles (CURL),
- Content-Length : longueur du fichier en octets.
- L’en-tête HTTP lors de l’acquisition du cache
- Le contenu de la page
Ce qui va bien-sûr nous intéresser, c’est le contenu de la page, ce dernier est, tout comme l’en-tête HTTP, affiché via deux méthodes d’encodage, nous avons à gauche : de l’hexadécimal et à droite : de l’ASCII.
-

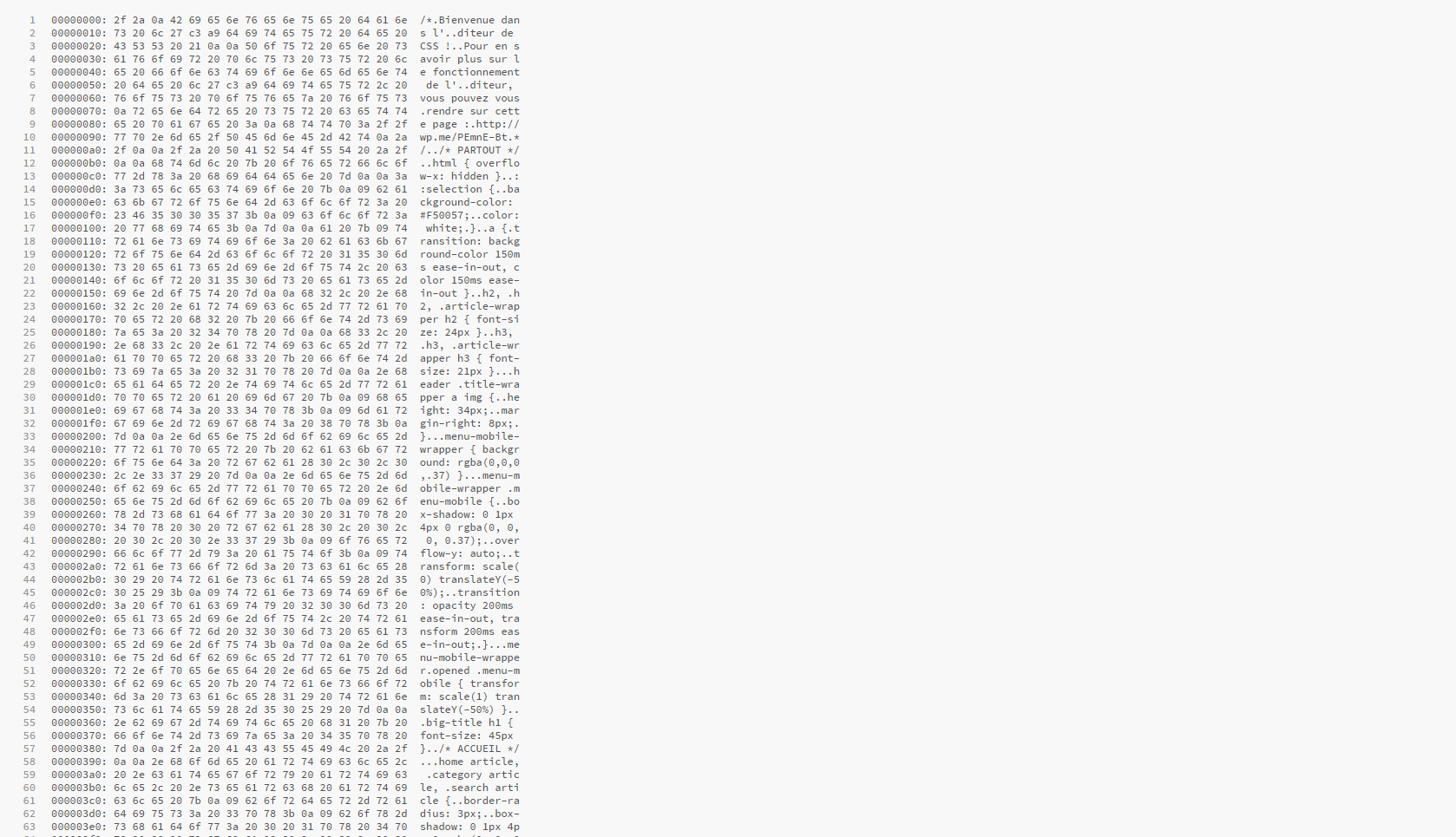
- (1 sur 7) Je sélectionne le code qui m’intéresse,

-
- (2 sur 7) je le colle dans un I.D.E.,
-
- (3 sur 7) je supprime le code hexadécimal et remet le code ASCII sur une ligne,

-
- (4 sur 7) j’enregistre le fichier dans son langage pour bénéficier de la colorisation syntaxique,

-
- (5 sur 7) je supprime un maximum de points engendré par l’ASCII (et il en reste),

-
- (6 sur 7) je réalise des retours à la ligne à chaque sélecteur,

-
- (7 sur 7) j’indente mon code.
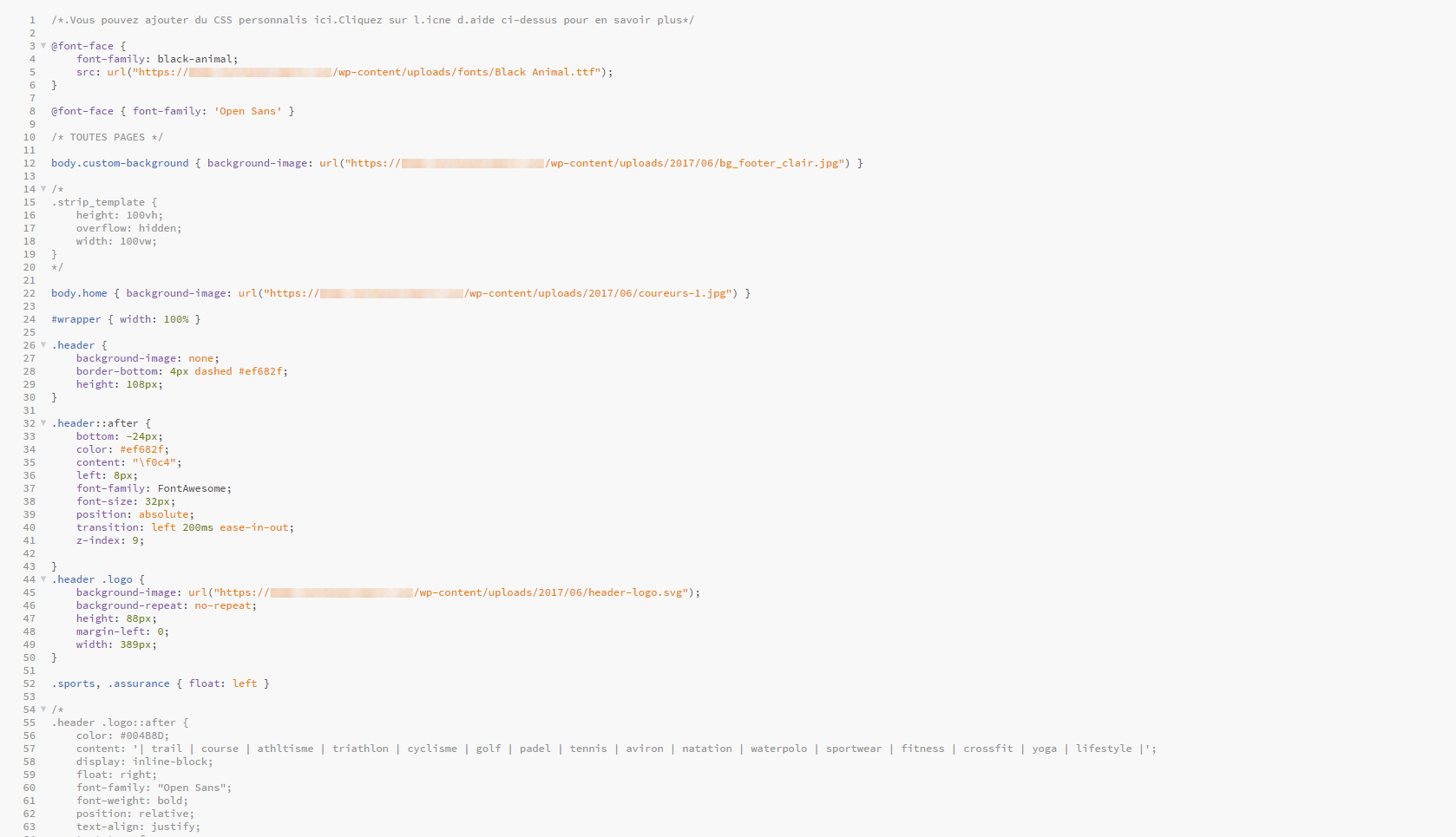
Voilà comment j’ai réussi, petit à petit, à récupérer un grand nombre de contenu de la base de données.
La morale de l’histoire
Mieux vaut prévenir que guérir.
– Anonyme
Il existe différentes façons de se prémunir de ce qui s’est passé mon côté :
- réaliser des sauvegardes qui seront stockées localement et sur le nuage*,
- vérifier vos sauvegardes,
- utiliser un logiciel de versioning tel que Git et le lier à GitHub.
*Par nuage, je parle des services de stockage Cloud qui permettent de mettre en ligne, sur un serveur privé, toutes les données qu’on lui envoie, cela vous permet de pouvoir les récupérer où que vous soyez et de ne pas perdre vos fichiers à cause d’une mauvaise manipulation.
Que faites-vous pour stocker vos données ? Avez-vous déjà eu un problème de ce genre ?
1 🔗 Définition de DNS selon Wikipédia
2 🔗 Définition de FTP selon Wikipédia
Aucun commentaire
Soyez le premier à commenter :)